経緯
某掲示板でAIイラストが貼ってあるのを見てやってみたいと思っていた。
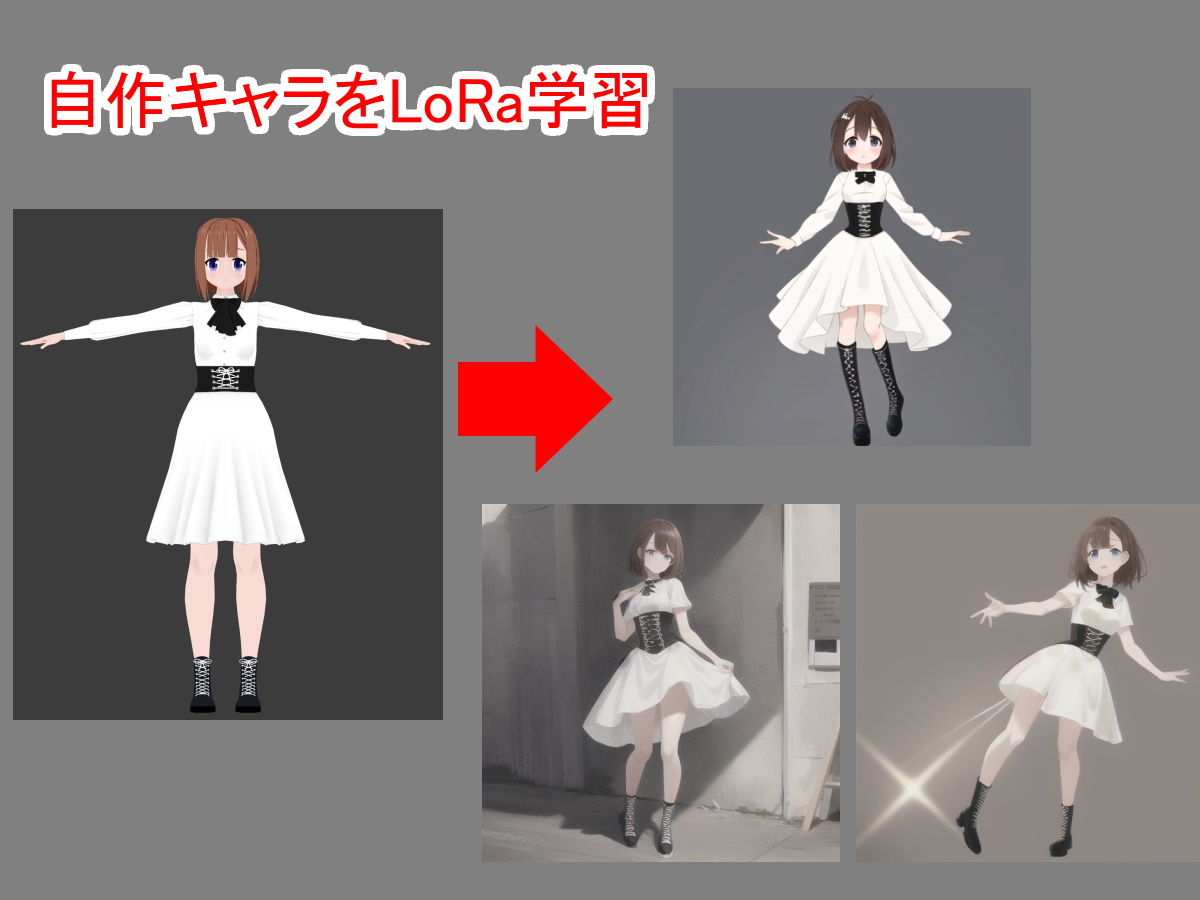
せっかくやるなら既存のキャラではなく、自作キャラでAIイラストを作ってみたかった。
AIイラストを調べていると有料のサービスが多く、できれば無料で出来ないか探していた。
Stable DiffusionのWebUI Automatic1111を使用してLoRa追加学習モデルを作れば自作キャラが作れると解説されていた。
今回は、前述のツールでイラストを作成していく。
学習用画像作成
Blenderで作成したモデルにポーズをとらせて、スクリーンショットで画像ファイルにする。
適当にポーズをとらせて画像を12枚作成した。

LoRaモデル作成
モデルの作成は、youtubeの解説動画があったので参考にした。
手順通りに進めれば簡単にできた。
出来たファイルを「models」フォルダに格納したら追加学習データの準備完了。

Pythonのインストール(2025,1,25追記)
Pythonのインストールを行います。
使用するバージョンは「3.10.6」を使用します。

Windowsの64bit版をダウンロードします。
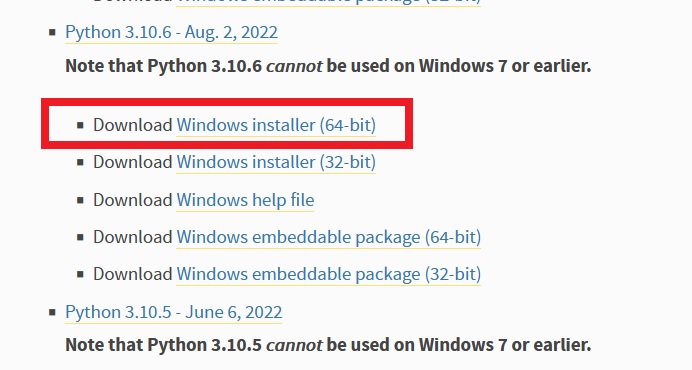
exeファイルからインストールを行います。
インストール画面下部に「Add Python 3.10 to PATH」にチェックを入れて、「Install Now」をクリックしてインストールします。
Gitのインストール(2025,1,25追記)
Gitのインストールを行います。

exeファイルを起動して何も設定を変えずに次に進んでインストールを行います
基本モデル入手
追加学習のデータが完成したら、次は基本のモデルデータを入手する。
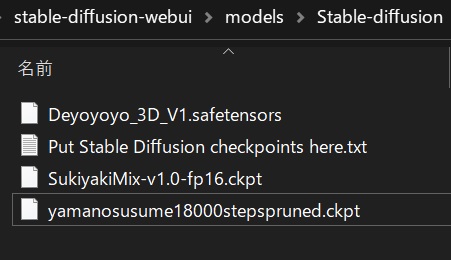
今回は3つのモデルを使う。
・yama-no-susume
アニメ版ヤマノススメを元ににしてるらしく、アニメ調が濃く出ている。
https://huggingface.co/alea31415/yama-no-susume/resolve/main/examples/with_inpaint/00014-225925947.png・SukiyakiMix-v1.0-fp16
繊細で綺麗な感じが出ている。
https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example1.png・Deyoyoyo_3D_V1
繊細でディテールが素晴らしい。
モデルをダウンロードしたら「stable-diffusion-webui → models → Stable-diffusion」の中にファイルを格納する。
ネガティブプロンプト拡張機能追加
イラストの質を向上させるプロンプトを追加していく。
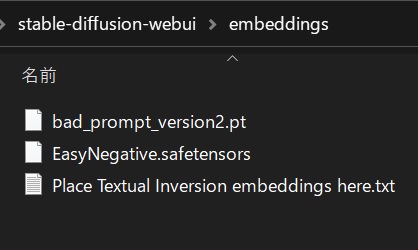
今回使用したのは「EasyNegative」「bad_prompt」を使用する。
・EasyNegative
イラストのクオリティを向上してくれるらしい。

・bad_prompt
手の修正に特化していて手の破綻の軽減をしてくれるらしい。

ファイルをダウンロードしたら「Cstable-diffusion-webui → embeddings」内にファイルを格納する。
WebUI起動
「webui-user.bat」をダブルクリックしてバッチファイルを実行する。
成功したら以下の画像のようになり「http://127.0.0.1:7860」をWebブラウザに貼り付ける。
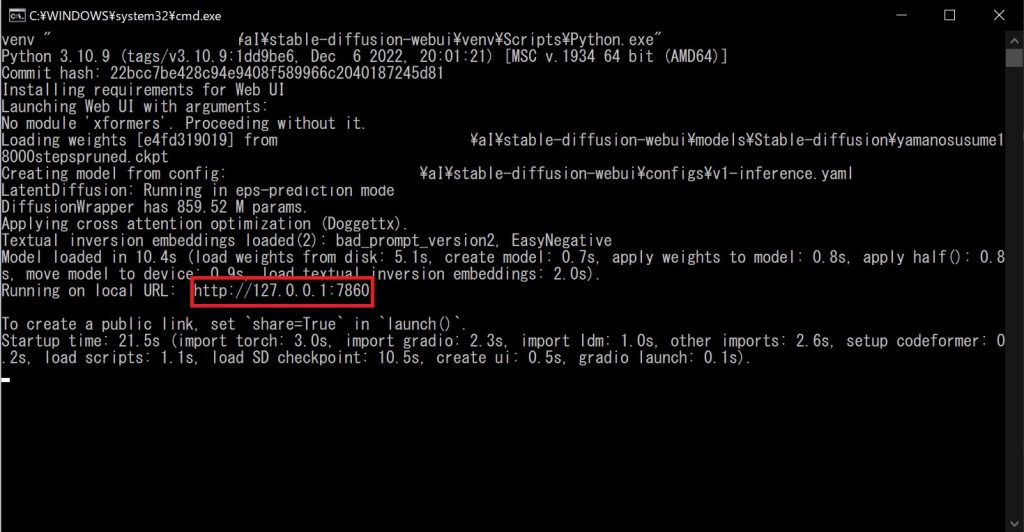
以下のように表示される。
初めにネガティブプロンプトを入力する。
画面右端の赤枠のアイコンをクリックする。
画面左の赤枠アイコンをクリックすることでネガティブプロンプトを追加できる。
ここでは「EasyNegative, bad_prompt_version2:0.8」という感じに間に「,」を挟む必要がある。
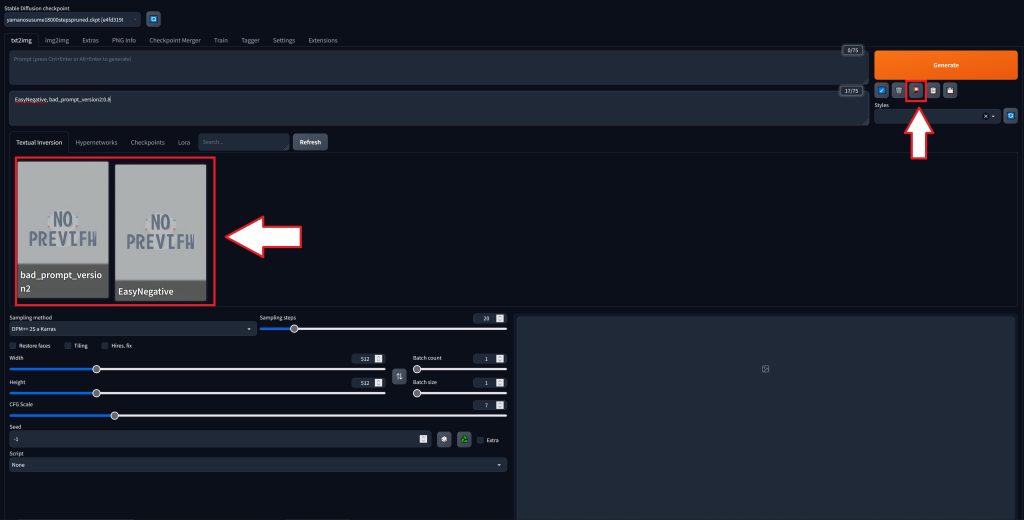
次にポジティブプロンプトを入力する。
「Lora」タブをクリックして自作データをクリックすると「<lora:orikyaraV2:1>」が追加される。
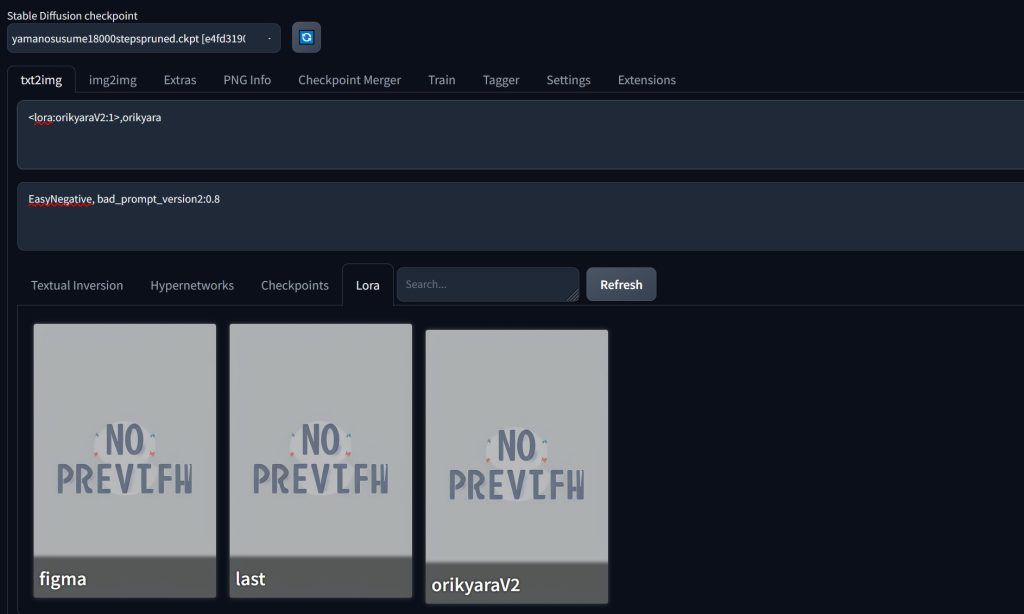
AIイラストを出力(yama-no-susume)
準備が出来たから画像を出力していく。
画面右端の「Generate」をクリックして実行する。
6回ほど出力した画像は以下のようになった。






なぜか人外キャラが出力された。
原因を調べているとポジティブプロンプトの「<lora:orikyaraV2:1>」が悪いとわかった。
設定値を「1」にしたのが悪く0.3ぐらいに落とした。
ついでにワードも追加してみた。
<lora:orikyaraV2:0.3>, orikyara, detailed eyes, best quality,masterpiece,ultra high res, white dress, long sleeves, boots,corset, brown hair








元絵と比較してみよう。
髪型はショートヘアーで出力画像に濃く反映されている。
服装も白のワンピースの形状を再現出来ていて首元のリボン、コルセットも反映されている。
靴はショートシューズからロングシューズにされている。
概ね満足いく結果が得られた。
AIイラストを出力(SukiyakiMix-v1.0-fp16)
次はSukiyakiMix-v1.0-fp16で出力してみる。









さっきとは画風がかなり変わったが、モデルの構成がきちんと反映されている。
AIイラストを出力(Deyoyoyo_3D_V1)
最後はDeyoyoyo_3D_V1で出力してみる。








背景がシンプルに出力されたが綺麗なイラストが出力された。
感想
初めてのAIイラストは難易度が高いと思ってたが簡単に出来ておどろいた。
ドラゴンが出力されたときはモデル作成の時に間違えたかと思ったが調整が大事だと感じた。
呪文とか完璧に理解していないが他の投稿者のようなイラストを生成できるようにしていきたい。


コメント